
Trying to Deliver Results: Three lessons in designing — and redesigning — a new program
[Editor’s Note: This is the second blog post in a series highlighting key lessons from the new paper — Citizen Voices, Community Solutions: Designing Better Transparency and Accountability Approaches to Improve Health — from the Transparency for Development Project. Transparency for Development is a joint project of the Harvard Kennedy School’s Ash Center for Democratic Governance and Innovation and Results for Development that seeks to answer the questions of whether community-led transparency and accountability can improve health — and in what contexts. Read the first post, “Reinventing community scorecards.”]
There is a growing movement to embrace uncertainty and complexity in international development programs — and to design evaluation tools and systems that help development actors do their work in the context of this uncertainty. This means using evaluation not just for accountability (Did the program work?), but rather to help implementers search for and refine solutions that work in a given setting (How can we experiment, measure, iterate and adapt to make your program work better?).
As with any new agenda (and especially for “early adopters”), it takes time to turn principles into practice and distill lessons from the journey. At R4D, we’ve been on our own journey, using a mix of research and experimental methods — what we refer to as evaluation and adaptive learning — to design, test and adapt better programs.
For me, this journey started with our Transparency for Development (T4D) project a little over five years ago.
As part of the T4D project, we recently released a working paper describing the intervention we designed and implemented in hundreds of communities in Tanzania and Indonesia. Soon, we’ll be able to measure impact; the endline of our evaluation was conducted this summer. While we await this data, I wanted to take stock of the lessons our team learned about experimentation and adaptive learning in the context of a real program.
1. Embrace and articulate your areas of uncertainty and make them the focus of early, quick and lean testing
All programs require design choices, and ours was no exception. As Pritchett et al. note, anyone seeking to bring even a “best practice” randomized controlled trial-tested program, such as cash transfers, to a new setting would have to make many detailed choices about program structure in order to actually deliver the program. For example: Who is eligible? How large is the transfer? How are conditionalities enforced?
In our case, we did have a “proven” program — a community scorecard intervention that was shown to reduce under-5 mortality by nearly one-third. But we were adapting it to different contexts (Tanzania and Indonesia), and to a different, although related, problem: maternal and newborn health. We also had a new set of principles that we wanted to use to modify the intervention, including:
- Co-designed with in-country partners
- Health-focused, not health-service-delivery-focused
- Locally relevant
- Community-driven
- Non-prescriptive
- Largely free of outside resources
As we tried to adapt the intervention, we had endless debates about intervention details: What information should we present to communities? Should communities or professional enumerators collect health statistics? Who should be included in community meetings? How should “action planning” be facilitated?
After one especially protracted afternoon of debate, we decided to just start trying to implement small, if imperfectly designed pieces of the intervention. This idea of “pre-piloting” was based on the idea that we shouldn’t wait to resolve key design questions in a one-time pilot of a relatively complete intervention. Like the philosophy underlying “rapid prototyping” or the lean startup movement’s “minimum viable products,” the idea was that it was better to try discrete intervention choices quickly, get feedback (and, oftentimes, fail), rather than to build too many assumptions into a single pilot.
This decision sparked discussion about which assumptions were truly the most important to test and how would we go about doing it. For example, instead of assuming that community members would be motivated to work on maternal and newborn health issues, we put together a quick community meeting to see how engaged people would be (quite engaged, it turns out). Instead of debating how selection of participants in community meetings would affect meeting dynamics (Would including health volunteers dampen or overpower the participation of disempowered women?), we tried meetings with different combinations of community members. And we learned that the elites clearly dominated, and, thus, were ultimately excluded from meetings.
2. Collect as much feedback as possible from your pilot, even if it’s still too small for more rigorous testing
After “failing fast” on a number of different fronts during our lean testing, we were ready to move on to piloting a more complete version of the intervention. We still planned to only implement the program in a handful of communities at a time in each country, at too small of a scale to do much rigorous quantitative analysis. But we wanted to learn as much from our pilots as possible.
We ended up conducting many rounds of piloting in different regions of both Tanzania and Indonesia, over the course of nearly 18 months, letting the lessons of one round in piloting inform and improve the next. While it may have taken longer to get to a “final” design, we were able to more systematically confirm our program’s logic model, as well as how to best deliver the program.
We also piloted alternative approaches simultaneously, for example, trying one approach in three communities while testing another in three other neighboring communities. As a result, we dropped approaches that clearly weren’t working (for example, we learned that community members themselves were very poor data collectors), in favor of alternatives (using program staff as data collectors for some information while also leveraging existing national surveys) without losing valuable time.
For other design choices, it wasn’t as easy as discarding an obviously failed approach, but rather trying to choose which approach would likely work better, leading to a program with a higher impact. With more time and resources, we could have used simple monitoring data as a part of a process evaluation to help us assess and make informed decisions. In subsequent projects at R4D, we’ve taken this approach — we have used a mix of quantitative and qualitative feedback to systematically validate a theory of change and to guide our decisions about which components to incorporate in our next iteration of a program design and which to drop.
3. RCTs and adaptive learning approaches are complements, not substitutes
Should we use structured experiential learning in place of programmatic impact evaluation? Our experience has led us to believe that this would be a mistake. These two approaches are complements, not substitutes.
In T4D, we learned about the benefit of incorporating relatively simple feedback, and more structured experimentation, on the front end of the design processes. We learned a huge amount about our program, and are confident that we improved program design in the process. But human behavior is complex, and there are too many examples of well-designed programs that nonetheless have no apparent effect on outcomes.
So, while we’re confident we’re testing a stronger version of this intervention than we would have without early experimentation and feedback, we still don’t know if it will have a measurable and identifiable effect on health outcomes. For that, we’re glad that we have an RCT in progress. I’d also argue that knowing we were going to have to evaluate our impact on outcomes was a strong “pull” to keep us challenging our assumptions and trying to get the design right.
What can we take away from these lessons?
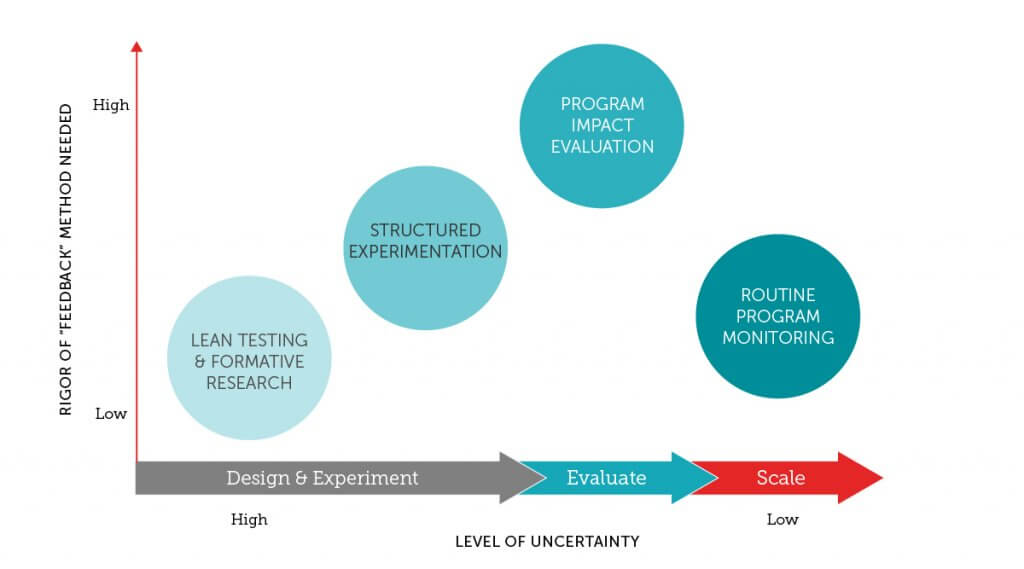
While the debate over the right level of rigor in monitoring and evaluation in development continues, the level of quantitative rigor (or sophistication, in M&E methods) you should use to evaluate a program is inversely proportional to the amount of certainty you have about your program’s design. The more uncertain you are about the design of any program component, the less rigor you need, since failure is more likely than success. You can test quickly and on a small scale, fail at times, and, in doing so, eliminate clearly flawed design choices.
To that end, we didn’t need rigorous measurement to see that community members were not interested in collecting data on community health outcomes. As you eliminate sources of failure, more structured feedback and more objective data collection within the piloting process can further refine program design.
Developing a program that delivers results is hard. But we believe that we can do better with “smarter” piloting, iteration and adaptation during the design process. This ensures that the significant time, effort and technical inputs to rigorously evaluate is more likely spent on programs without design flaws that could have been surfaced more easily and cheaply earlier on.
Photo © Results for Development/Courtney Tolmie